RF-DETR inference speed benchmarking
At work we use RF-DETR models in factories for various purposes. Here, inference speed is our main bottleneck. We primarily run our AI on-premise, using various NVIDIA Jetson devices. At editor.kexxu.com we provide RF-DETR training for various model sizes, at various image resolutions. To get an idea of the best model to use in our factories, I decided to benchmark the different models and see what precision & resolution combinations would make the most sense in our situation. Perhaps these results interest someone else, so I decided to post the results here.
All tests were done on a Jetson Orin NX with the following specs:
| Device | NVIDIA Jetson Orin NX (8GB) |
|---|---|
| CPU | 6-core Arm® Cortex®-A78AE (1.98 GHz max) |
| GPU | 1024-core NVIDIA Ampere w/ 32 Tensor Cores (765 MHz max) |
| DLA | 1x NVDLA v2.0 (614 MHz max) |
| RAM | 8GB LPDDR5 (128-bit, 102.4 GB/s) |
| Total AI Perf | 70 TOPS (INT8) |
| JetPack Version | R36 (release) 4.3 |
| CUDA Version | V12.6 |
| Power Mode | 20W |
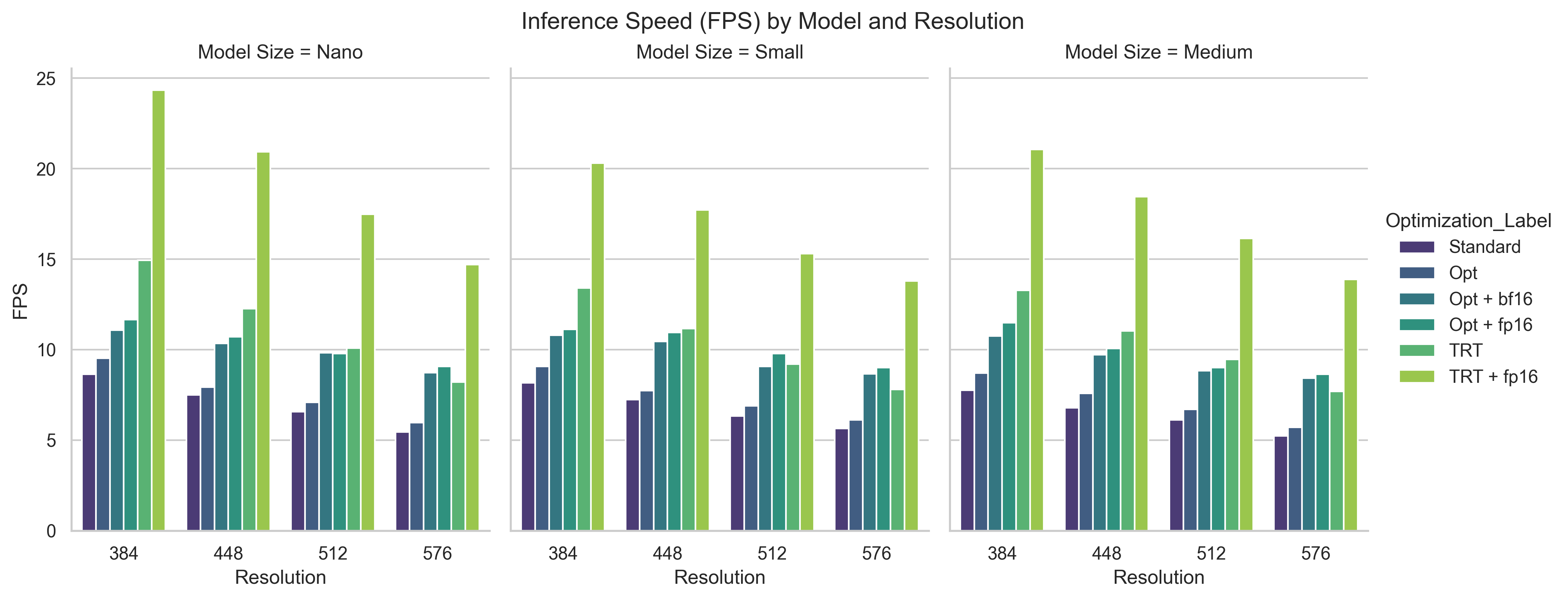
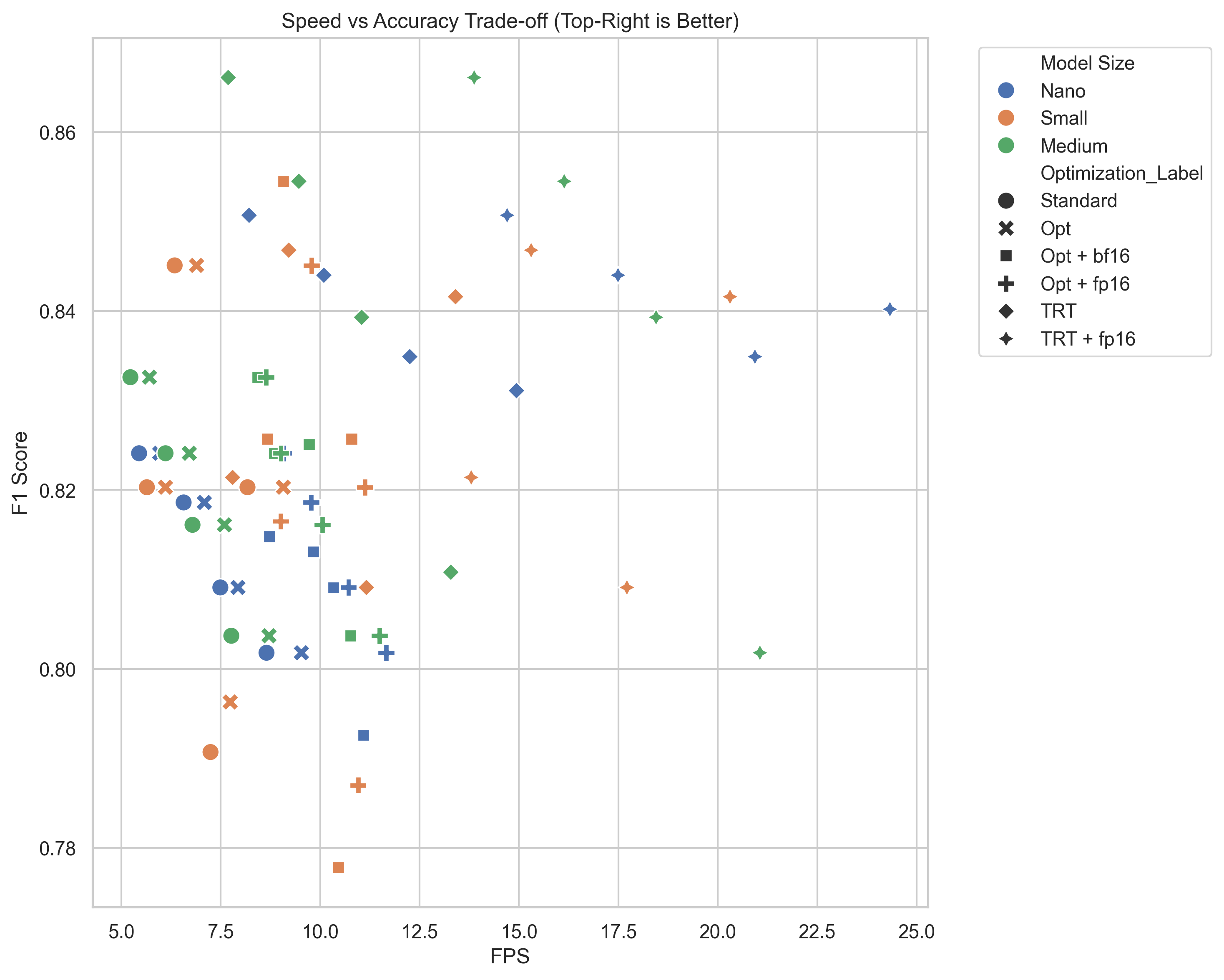
As can be seen in the figure below, the speedup gained from using TensorRT with FP16 is roughly the same across the board. Notably, TRT really starts to shine when you use FP16 precision.
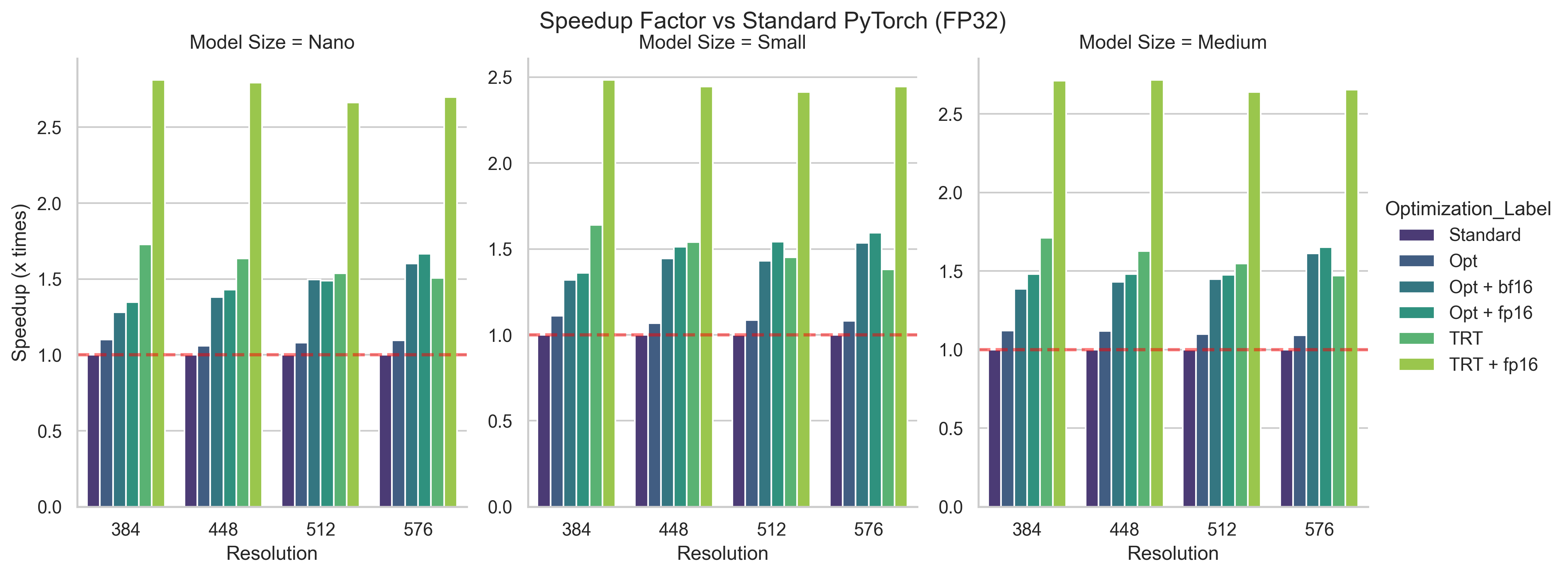
I performed these tests on a somewhat simple task, meaning the accuracies were all somewhat similar. For this reason, the accuracy metrics should be taken with a grain of salt. Despite this, I'll still provide the following plot, which can perhaps be used as some weak prior to decide what model to first test out for your use case.